1. Introduction and Motivation
In previous notes, we explored Policy Gradient (PG) methods (e.g., REINFORCE). While elegant and capable of handling continuous action spaces, PG methods suffer from a significant drawback: high variance. The gradient of the reinforcement learning objective is given by:
Where is an estimate of the return (reward to go). In REINFORCE, we use the Monte Carlo estimate (the actual sum of rewards observed in the rollout). Because trajectories can vary wildly due to stochasticity in the environment and policy, this estimate has very high variance, leading to unstable training and poor sample efficiency.
Actor-Critic algorithms aim to reduce this variance by replacing the high-variance Monte Carlo return with a lower-variance function approximator (the Critic).
2. The Actor-Critic Architecture
An Actor-Critic algorithm consists of two components:
- The Actor (): The policy that controls how the agent acts. It tries to maximize the expected return.
- The Critic (): A value function that estimates the expected return of the current policy. It evaluates the actor's actions.
2.1. The One-Step Actor-Critic Algorithm
The interaction between the Actor and Critic creates a cycle where the Actor generates usage data, and the Critic learns from this data to provide better updates for the Actor.
Below is the standard One-Step Actor-Critic algorithm (online, episodic). Notice how the Critic's value estimate is used to compute the TD-error , which then drives the updates for both the Actor and the Critic.
2.2. Policy Evaluation (Training the Critic)
The Critic's role is to evaluate the current policy by estimating the value function . To perform the Update Critic step shown above, we treat Policy Evaluation as a regression problem. The critic minimizes the Mean Squared Error (MSE) between its prediction and a target value .
The gradient of this loss determines the update direction: . In the algorithm above, the term corresponds exactly to the TD error when using the Bootstrapped Target.
2.2.1. The Choice of Target: Bias vs. Variance
The crucial difference between Actor-Critic and methods like REINFORCE lies in the choice of the target .
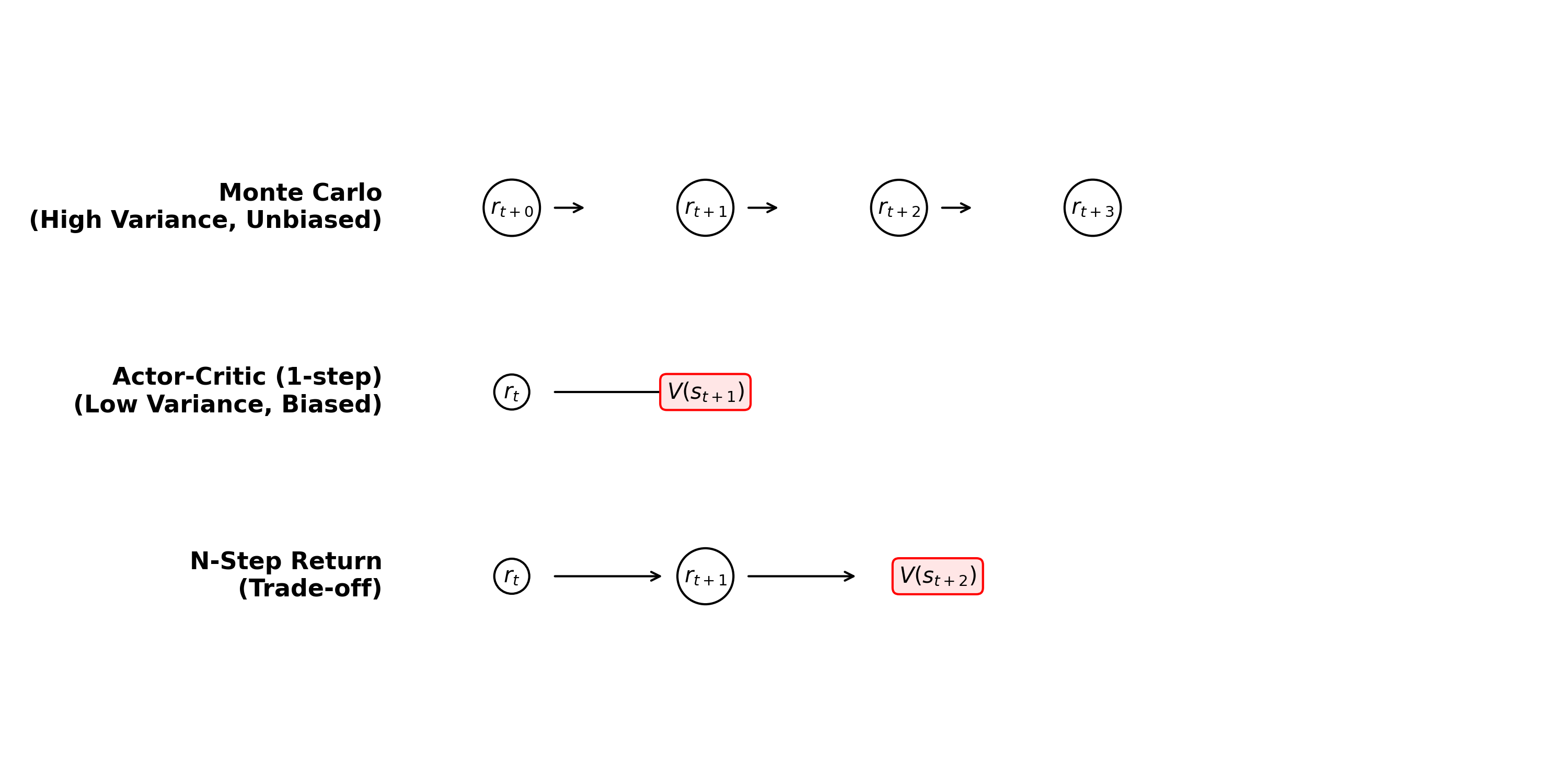
- Monte Carlo Target (REINFORCE): Uses the actual sum of rewards from the entire episode.
- Bootstrapped (TD) Target (Actor-Critic): Uses the immediate reward plus the estimated value of the next state.
Using the bootstrapped target introduces bias (because is initially an incorrect estimate) but significantly reduces variance.
Rigorous Variance Decomposition:
To understand mathematically why bootstrapping reduces variance, we can use the Law of Total Variance to decompose the variance of the full Monte Carlo return . We condition on the random variables of the immediate step, :
- Term A (Immediate Variance): The variance arising from the randomness of the current step (action choice , immediate reward , and transition to ).
- Term B (Future Variance): The expected variance of the rewards from time onwards. In Monte Carlo, this sums up the noise of every future coin flip (stochastic actions and transitions) for the rest of the episode. This term is positive and typically large for long horizons.
The Actor-Critic Advantage: By using the TD target , we are effectively choosing to ignore Term B. We replace the highly variable future return with its deterministic expectation (assuming our critic is accurate).
Thus, the Critic "cuts off" the accumulation of noise from the future, leaving only the variance from the immediate step (Term A). This leads to strictly lower variance updates, ensuring more stable training.
2.3. Policy Improvement (Training the Actor)
The actor is updated using the approximate advantage calculated by the critic.
Where the advantage estimate is often approximated using the temporal difference error (TD-error):
2.4. The Challenge of Off-Policy Actor-Critic
A common question is: "Can we just use a Replay Buffer to train Actor-Critic?" to improve sample efficiency.
- Directly training the policy on old samples (transitions from a buffer) is mathematically incorrect for standard Policy Gradient because the gradient requires samples from the current policy distribution .
- Using old samples introduces distribution shift, meaning the gradient estimate is no longer valid for the current policy.
- Naive "Off-Policy AC" that treats old samples as current samples is often considered "broken". Correct Off-Policy algorithms require specific corrections (e.g., importance sampling) to handle this mismatch.
3. Bias-Variance Tradeoff and N-Step Returns
The choice of target for the critic dictates the bias-variance tradeoff:
-
Monte Carlo (REINFORCE): Unbiased, High Variance.
-
One-step Actor-Critic: Biased (if Critic is imperfect), Low Variance.
-
Discount Factor as Variance Reduction:
- Lower (ignoring far-future rewards) significantly reduces variance but introduces bias (we optimize for a "myopic" horizon).
- High (near 1) is unbiased (w.r.t true objective) but has high variance.
3.1. Variance Comparison
The concept of "cutting off" the variance is visualized below:
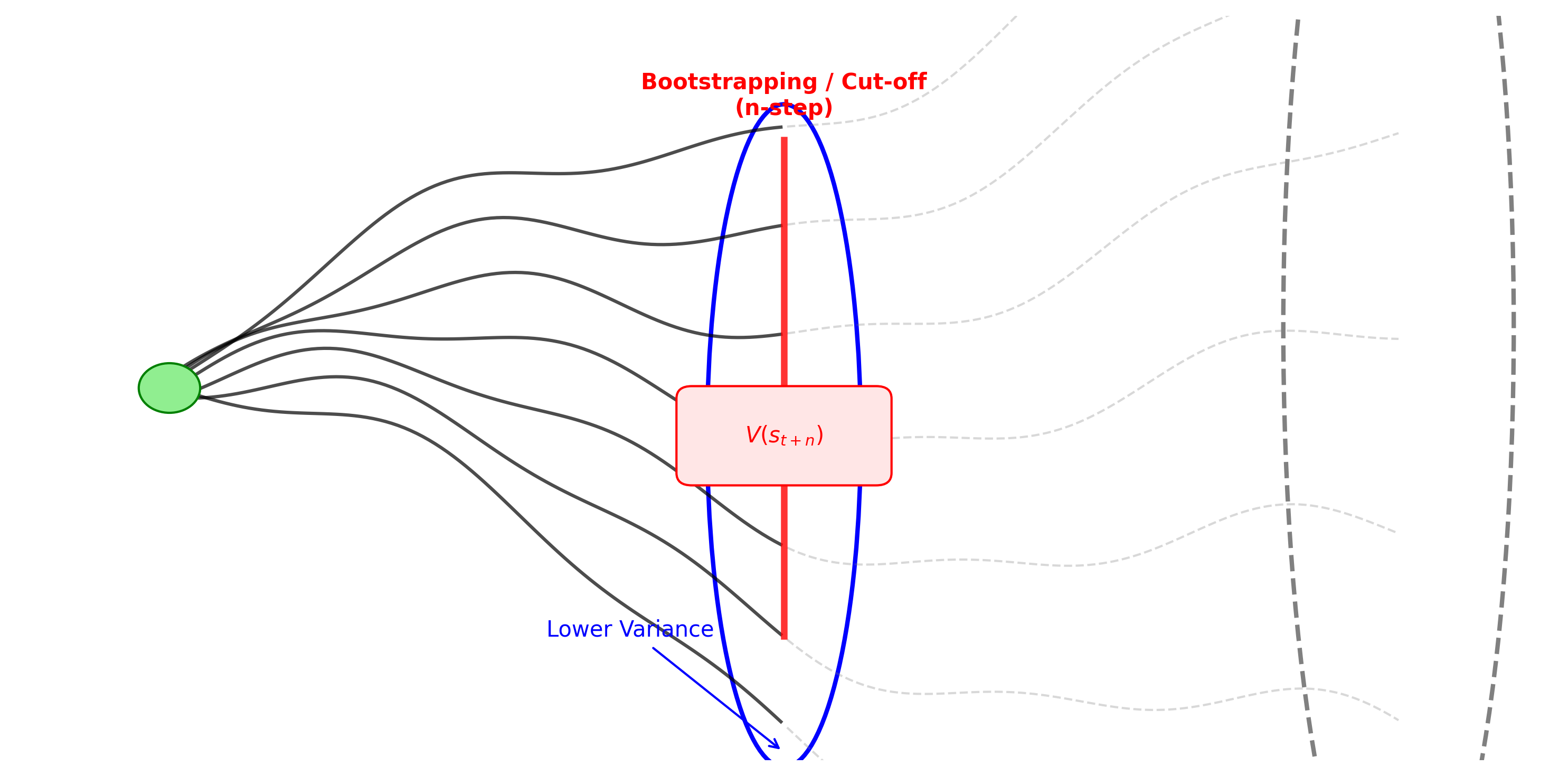
To understand why the Critic reduces variance, let's compare the variance of the Monte Carlo return () versus the Bootstrapped TD Target ().
1. Variance of Monte Carlo Return (): The MC return is the sum of all future discounted rewards. Assuming rewards at each step are independent random variables with variance :
Even with discounting, this variance accumulates from every future time step.
2. Variance of TD Target (): The one-step TD target only involves the immediate reward and the estimated value of the next state .
If the value function is a good estimator (or effectively constant/learned), its variance is typically much lower than the sum of all future reward variances.
Essentially, we replace the "infinite tail" of variance () with the single term variance of our estimator .
We can interpolate between these using n-step returns:
3.2. Generalized Advantage Estimation (GAE)
Instead of choosing a single (which is a hard hyperparameter to tune), Schulman et al. (2015) proposed GAE, which computes an exponentially weighted average of all possible n-step returns.
The key insight is to define the TD error at time as:
This is actually the bias-corrected estimate of the advantage for just one step.
The GAE Estimator is defined as the sum of discounted TD errors:
Why is this useful?
- as a Knob: The parameter allows us to smoothly interpolate between the high-bias TD target and the high-variance MC return.
- : . This is equivalent to TD(0) (low variance, high bias).
- : . This is equivalent to Monte Carlo (high variance, unbiased).
- Robustness: By averaging multiple k-step returns, we are less sensitive to the specific choice of exactly "how many steps" to look ahead.
Implementation Note
We don't actually compute infinite sums. We compute GAE efficiently by iterating backwards from the end of the trajectory:
This recursive form is and very easy to implement in code.