This is the first post of a series of notes on reinforcement learning. The aim for this series is to document my understanding of RL and provide a minimal level of knowledge (but with reasonable amount of mathematical rigor) for engineers to get started with RL.
1. The Goal of Reinforcement Learning
The goal is to learn a policy that maximizes the expected return .
Where is a trajectory and is the probability of the trajectory under policy :
Where the notation is defined as follows:
- : State at time step .
- : Action at time step .
- : Reward function.
- : Policy with parameters .
- : Transition dynamics of the environment.
- : Initial state distribution.
- : A trajectory sequence .
- : Probability of observing trajectory under policy .
- : Cumulative return of trajectory .
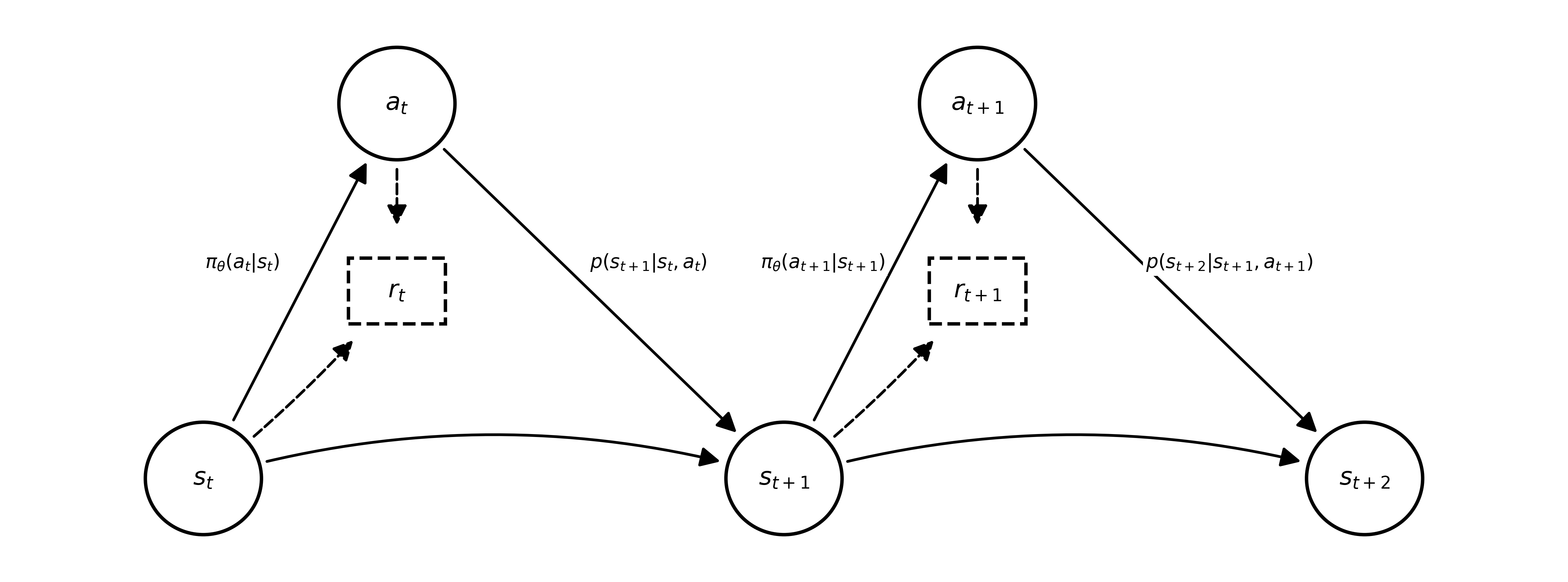
The following diagram illustrates the relationship between these variables in a Markov Decision Process (MDP):
2. The Policy Gradient
We want to update in the policy with . Using the log-derivative trick: , we get:
Expanding , the terms involving the dynamics do not depend on , so their gradient is zero. We are left with:
Interpretation
This equation decomposes the gradient into two parts:
- Policy Direction: represents the direction in parameter space that increases the probability of the actions taken in the trajectory.
- Trajectory Reweighting: acts as a scalar weight.
The gradient update pushes the policy parameters in the direction of trajectories that yield high cumulative rewards ("trial and error"). Formally, it scales the gradient of the log-probability of the trajectory by its return.
The REINFORCE Algorithm
The REINFORCE algorithm (Williams, 1992) is the simplest implementation of the policy gradient. It uses Monte Carlo sampling to estimate the return .
Since it relies on the full trajectory return (Monte Carlo), REINFORCE is unbiased but suffers from high variance, often leading to slow convergence.
Why is variance high?
- Stochasticity: In a standard MDP, both the policy and the environment are stochastic. A single sampled trajectory is just one realization of a highly variable process. High-probability paths might yield low rewards due to a few unlucky transitions, and vice-versa.
- Difficulty in Credit Assignment: REINFORCE uses the total return to update all actions in the trajectory. If a trajectory has a high return, the algorithm reinforces every action taken, even if some were suboptimal. Without a critic to evaluate individual states, the signal ("good" or "bad") is smeared across the entire sequence, introducing significant noise.
- Magnitude of Returns: The gradient updates are scaled by the return . If returns vary wildly in magnitude (e.g., one path gives 0, another gives 1000), the gradient updates will swing violently, destabilizing the learning process.
3. Variance Reduction
The standard policy gradient estimator has high variance. We can reduce this variance using two main techniques: Causality and Baselines.
3.1 Exploiting Causality (Reward-to-Go)
The policy at time cannot affect rewards obtained in the past (). Therefore, we can replace the total return with the reward-to-go:
The term is often denoted as .
3.2 Baselines
We can subtract a baseline from the return without introducing bias, as long as the baseline does not depend on the action :
Thus, the policy gradient with a baseline is:
A common choice for the baseline is the average reward or a learned Value Function . This significantly reduces variance.
4. Implementation
In automatic differentiation frameworks (like PyTorch or TensorFlow), we don't compute the gradient manually. Instead, we construct a "surrogate loss" whose gradient equals the policy gradient.
Where is the estimated advantage (e.g., ). We treat as a fixed constant (detach from graph) during backpropagation.
Algorithm:
- Sample: Run policy to collect trajectories .
- Estimate Return: Compute reward-to-go and optionally fit a baseline .
- Update: Compute gradient and update .
Suggested Readings
- Williams (1992): Simple statistical gradient-following algorithms (REINFORCE).
- Sutton et al. (2000): Policy Gradient Theorem.
- Schulman et al. (2015): Trust Region Policy Optimization (TRPO).