Further thinking on DINOv3
The release of DINOv3 isn't just about scaling. In fact, DINOv3 is a story about how Scaling Laws do not naturally apply to ViT-based self-supervised learning.
In Vision Transformers Need Registers (Darcet et al., 2023) and DINOv3 (Oquab et al., 2025), researchers found that simply increasing scale leads to two distinct types of "blur" or feature degradation:
- A Failure of Storage (Architecture): As models scale in size and training time, they saturate their capacity to store global information. Without explicit registers, they "blur" the feature map with High-Norm Artifacts by repurposing background patches.
- A Failure of Signal (Objective): As training extends indefinitely, the global invariance objective ("DINO loss") prevents the maintenance of local details. This causes Dense Feature Degradation (Collapse), where the attention map becomes "diffuse" and spatial structure is lost.
Here is how DINOv3 transforms these bugs into features.
Part 1: High-Norm Artifacts (A Failure of Storage)
In DINOv2 (and many other large ViTs), researchers observed a strange phenomenon: specific background patches—like corners of the sky or shadows—would exhibit extremely high L2 feature norms, essentially acting as outliers.
Initially, these artifacts were dismissed as noise. However, in Vision Transformers Need Registers(Darcet et al., 2023), comparisons revealed that these high-norm tokens were actually holding global information.
The Instinct to Centralize
When a neural network architecture requires global information integration but lacks an explicit "global memory" or "scratchpad," it evolves a survival strategy: it "recruits" a subset of its input tokens to serve as temporary global storage.
This is the High-Norm Artifacts phenomenon, and it appears everywhere in deep learning:
- Vision (ViT Artifacts): The model needs a place to aggregate global info (e.g., "this is a dog"). It "hijacks" empty background patches because they contain the least local information, effectively turning them into a scratchpad (Darcet et al., 2023).
- NLP (Attention Sinks): In LLMs like Llama, the first token (
<s>) often has massive attention scores. Why? If a current token finds no relevant neighbors, the Softmax must still sum to 1. The model uses the first token as a "sink" to dump this probability mass (Xiao et al., 2024). - GNNs (Virtual Nodes): Graph networks struggle to pass messages across long distances. The solution is often to add a "Virtual Node" connected to everyone—a dedicated hub for global context (Gilmer et al., 2017).
The Fix: Explicit Registers
DINOv3 (and DINOv2-reg) validates this theory with a simple fix: Give the model what it wants.
By identifying this "instinct," the authors explicitly added 4 Register Tokens ([REG]) to the input sequence.
- Result: The model immediately stops hijacking background patches. The high-norm artifacts (outliers) disappear from the spatial map, as the signal moves entirely to the
[REG]tokens. - Verification: The paper confirms this by plotting token norms (Appendix D). The registers themselves take on extreme norm values (often "quantized" into distinct clusters), effectively absorbing the high-norm behavior so patch tokens can remain stable.
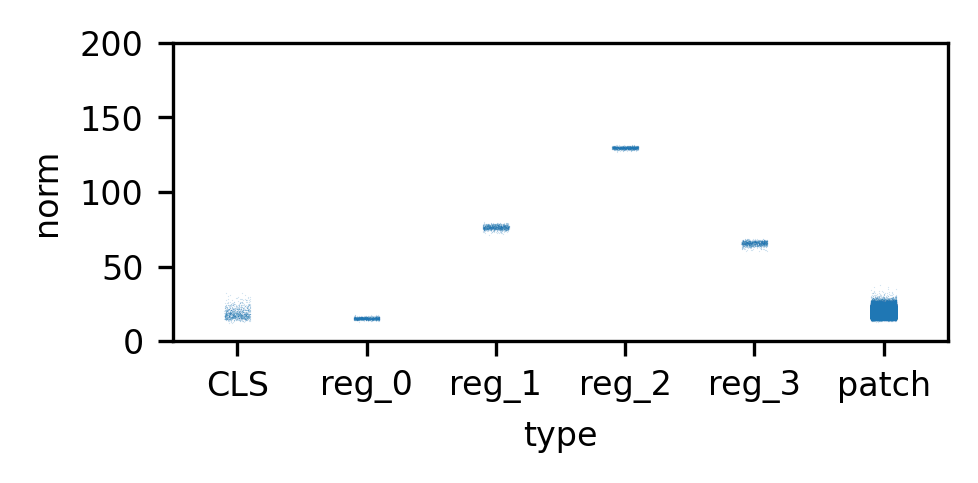
- Lesson: This turned an implicit "bug" (artifacts damaging background features) into an explicit "feature" (registers).
This aligns with architectural patterns in other fields:
- NLP: Recent efficient LLMs explicitly preserve "Sink Tokens" (often the start token) to absorb massive attention scores, preventing calculations from breaking on normal tokens (Xiao et al., 2024).
- GNNs: Explicit Virtual Nodes are added to graphs to handle global message passing, preventing the "bottleneck" effect on local nodes (Gilmer et al., 2017).

Part 2: Loss of Patch-Level Consistency (A Failure of Signal)
Fixing artifacts produces clean feature maps, but it doesn't solve the deeper problem of scaling. The DINOv3 paper describes an "unresolved degradation":
As training extends to 1M+ iterations (scaling steps) with larger data (scaling data), the Global Semantic performance (ImageNet accuracy) keeps rising, but the Local Geometric performance (Segmentation) crashes.
The paper identifies this as Dense Feature Degradation (or Loss of Patch-Level Consistency).
The Mechanism: Global Dominance
In DINOv3, this degradation is driven by the Global Invariance Objective (the "DINO loss").
- The Conflict: The model tries to maximize the similarity between global crops (using
[CLS]) while minimizing local reconstruction error. - The Collapse: As training progresses indefinitely, the model finds a "lazy" solution: it makes local patches align with the global
[CLS]token. - The Consequence: Spatially distinct patches lose their uniqueness and become semantically identical to the global image concept. The attention map becomes "diffuse," with irrelevant patches showing high similarity to the query merely because they all share global semantics.
This is not just a blurring effect; it is a fundamental Rank Collapse where the geometric structure of the image is sacrificed for marginal gains in global classification accuracy.
- Visual: The similarity maps become diffuse and noisy, with irrelevant patches showing high similarity to the query.

Input
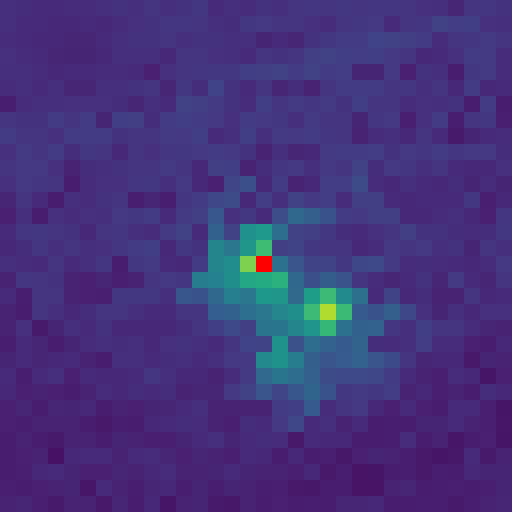
200k (Localized)
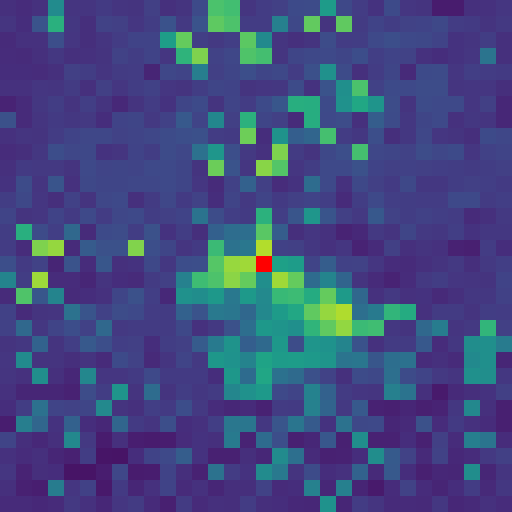
1M (Collapsed)
(As training extends indefinitely, the attention map explodes to cover the entire image, illustrating Rank Collapse.)
Deep Dive: Unique Challenges in Self-Supervised Vision
Why does this specific type of collapse manifest in DINOv3 but not typically in large Language Models (LLMs) or other Vision Transformers? The paper (and related literature) suggests this stems from the contradictory nature of the objectives involved:
-
Reconstruction vs. Contrastive Objectives (NLP vs. DINO):
- NLP Models (BERT/GPT): Typically use reconstruction objectives (Masked Language Modeling or Next Token Prediction). The model must predict a specific, concrete token (e.g., "cat" vs "dog"). If features were to collapse to a single global value, the model would fail to distinguish between vocabulary items, preventing the loss from decreasing. This objective naturally enforces the retention of local identity.
- DINOv3: Uses a Global Invariance Objective (Contrastive). The optimal mathematical solution to "minimize distance between views" is often to map everything to a constant. While architectural asymmetry (Teacher/Student) usually prevents this, at extreme scales, the model finds a way to satisfy the invariance constraint by discarding local diversity.
-
Static vs. Dynamic Targets (MAE vs. DINOv2):
- MAE (Masked Autoencoders): The target is Raw Pixels. Pixels are static ground truths that never change. The model is forced to retain geometric fidelity to reconstruct them.
- DINOv2 (iBOT): The target is the Teacher's features. The teacher is a dynamic entity (Exponential Moving Average). As training progresses to optimize global classification, the teacher itself begins to prioritize global semantics over local geometry. The student, trying to mimic this collapsing teacher, accelerates the degradation in a feedback loop.
The Fix: Gram Anchoring
To resolve this, DINOv3 introduces Gram Anchoring, which effectively acts as a regularization using early training states.
Since the current teacher (at 1M+ iterations) provides degraded dense features, the method anchors the student to a Gram Teacher derived from an earlier phase of training (e.g., 200k iterations) where the local consistency was still preserved.
One cannot simply stop the model from learning global semantics (which is desirable). It is necessary to decouple the features' specific values from their spatial relationships.
DINOv3 introduces Gram Anchoring:
- Gram Matrix: The method computes . This matrix captures the pairwise similarity structure between patches (the topological "fingerprint") regardless of their absolute feature values.
- Anchoring: It forces the student model to match the Gram Matrix of a "healthy" teacher (e.g., from early training or high-resolution inputs) just on these relationships.
This forces the model to preserve the geometric structure (local consistency) even as the feature values evolve to become more semantically powerful. This resolves the scaling issue, enabling "infinite" training schedules without losing density.

DINOv2: Noisy/Collapsed Features

DINOv3: Clean/Consistent Features
Summary
DINOv3 is a story of two corrections:
- Storage Correction: Recognizing that models will hack the data for storage (High-Norm Artifacts), and providing Registers to stop it.
- Signal Correction: Recognizing that global objectives destroy local consistency (Dense Feature Degradation), and using Gram Anchoring to preserve it.