Introduction
In previous discussion, we have shown power of pixel-based idiffusion models on a variety of dataset and tasks such as image synthesis and sampling. These models achieved state-of-the-art synthesis quality. In this post, we are going to discuss some recent works on conditional generation which means guide the generation process with additional conditions. A naive solution is to train a diffusion model specific on certain dataset and generate samples with it. However, more commonly, we want to generate samples conditioned on class labels or a piece of descriptive text. Building on this, an more sophisticated method is add label into input and, therefore, the diffusion process will take class information into consideration. However, due to performance reason, there are multiple algorithm have been proposed to achieve higher generation quality.
Classifier Guided Diffusion
In order to explicit utilize class label information to guide the diffusion process, Dhariwal and Nichol applying the gradient of a trained classifier to guide the diffusion sampling process.
There are three important components in this approach: classifier training, incorporate label information into diffusion model training and classifier-guided sample generation.
- Classifier training: A classifier can be exploited to improve a diffusion generator by providing gradient to the sampling process. Since the generated images at intermediate steps are noisy, the trained classifier should be able to adapt to these noises. Therefore, the classifier is trained on noisy images and then use gradients to guide the diffusion sampling process towards an arbitrary class label y.
- Adaptive group normalization: The paper incorporated adaptive group normalization layer into the neural network, where is the output of previous hidden layer and is obtained from a linear projection of the timestep and class embedding.
- Conditional reverse noising process:
The paper proved that the reverse transition distribution can be written in the form as .\
This can be observed from the following relationship:
where can be viewed as a constant since it does not contain .
We can write the reverse process(step 3) in DDIM's language. Recall that and we can write the score function for the joint distribution of as follows,
Therefore, we obtained the new noise prediction as
The paper provided detailed algorithms based on DDPM and DDIM.

Classifier-Free Guidance Diffusion model
Since training an independent classifier involved extra effort, Ho and Salimans proposed algorithm to run conditional diffusion steps without an independent classifier. The paper incorporated the scores from a conditional and an unconditional diffusion model. The method includes two components:
- Replace the previously trained classifier with the implicit classifier according to Bayesian Rule (opens in a new tab).
- Use a single neural network to function as two noise generators-- a conditional one and a unconditional one. It can be done by let for unconditional generation and for conditional generation towards class label . Therefore, the new noise generation function can be deduced as follows.
Latent Diffusion Models
Operating on pixel space is exceptional costful. For algorithms like diffusion models, it is even more demanding, since the recursive updates amplified this cost. A common solution in ML to deal with high dimensionality is embedding data into lower dimensional latent space. It is observed in Rombach et al. that most bits of an image contribute to perceptual details and the semantic and conceptual composition remains intact after undergoing aggressive compression. This motivates Rombach et al. to first embed the image into latent space, with models like VAE, then train a diffusion model in latent space. Moreover, it loosely decomposes the perceptual compression (removing high-frequency details) and semantic compression (semantic and conceptual composition of the data). In practice, a VAE can be used first to trimming off pixel-level redundancy and an U-Net backboned diffusion process can be used to learn to manipulate semantic concepts.
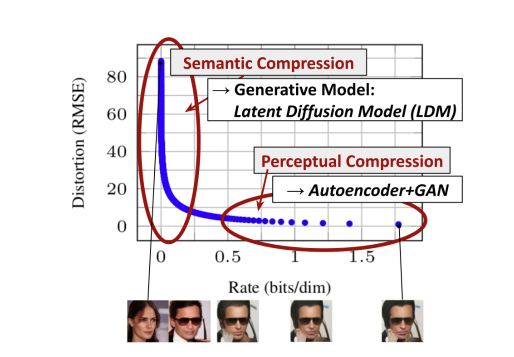
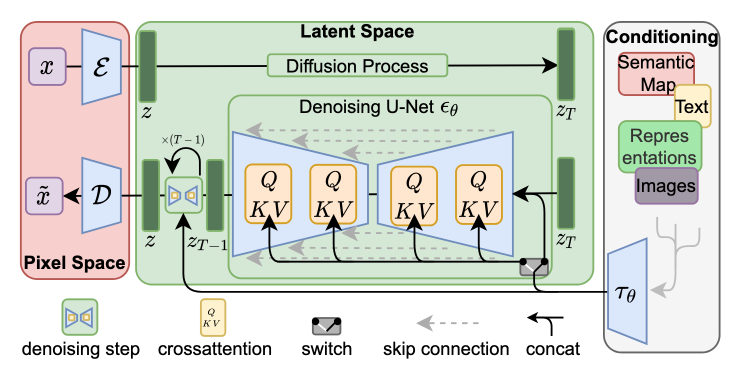
Methods
The perception compression process is depended on an autoencoder model. And encoder encodes an image in RGB space into a latent representation , and an decoder reconstructs the image from its latent . In contrary to other previous work, the paper use a two dimensional latent space to better suit the follow up diffusion model. The paper explored two types of regularization in autoencoder to avoid arbitrarily high-variance in the latent space.
- KL-reg: A small KL penalty towards a standard normal.
- VQ-reg: Uses a vector quantization layer within the decoder, like VQVAE but the quantization layer absorbed by the decoder.
The semantic compression stage happens in the latent space. After the autoencoder, the paper construct a diffusion model in latent space with U-Net being the backbone neural network. Denote the backbone neural network as and the loss function is
As in many other generative models and the topic of this blog, conditional mechanisms can be applied to this framework and, to be more specific, in the latent space. The paper implemented this by adding the additional inputs to the denoising autoencoder as . The additional inputs can be text, semantics maps or other "embedible information" like images and it aims to controll the synthesis process.
-
Due to the various modalities of the inputs, the paper first project the inputs to an "intermediate representation"(embedding) .
-
Cross-attention layer is used to apply controlling signal to the diffusion process through U-Net backbone. To be more specific, , with
Based on image-conditioning pairs, we then learn the conditional LDM via the loss
Experiments
The paper examine the model performance in two aspects:
- Enerated samples' perceptual quality and training efficiency
- Sampling efficiency
Perceptual Compression Tradeoffs

In this experiment, the paper compared FID/Inception scores under different downsample rate at different training steps. The experiment observed that LDM, with proper downsample rate, achieved siginificant better FID scores comparing with pixel-based diffusion model.
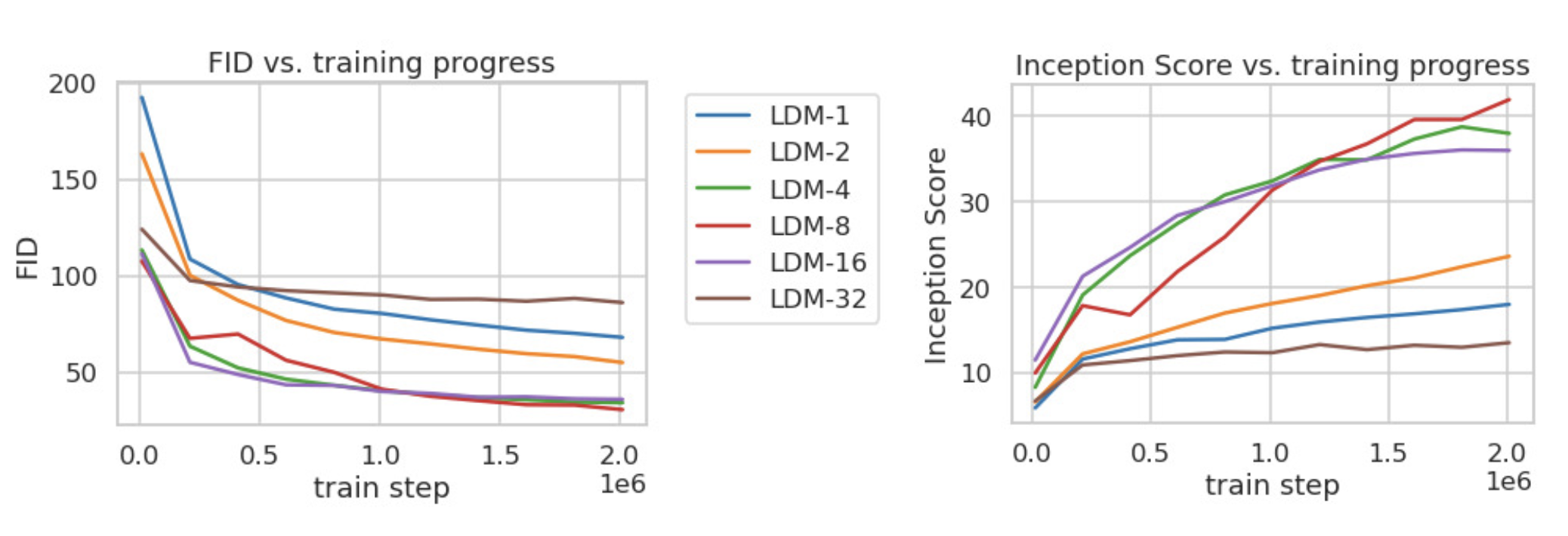
Sampling Efficiency
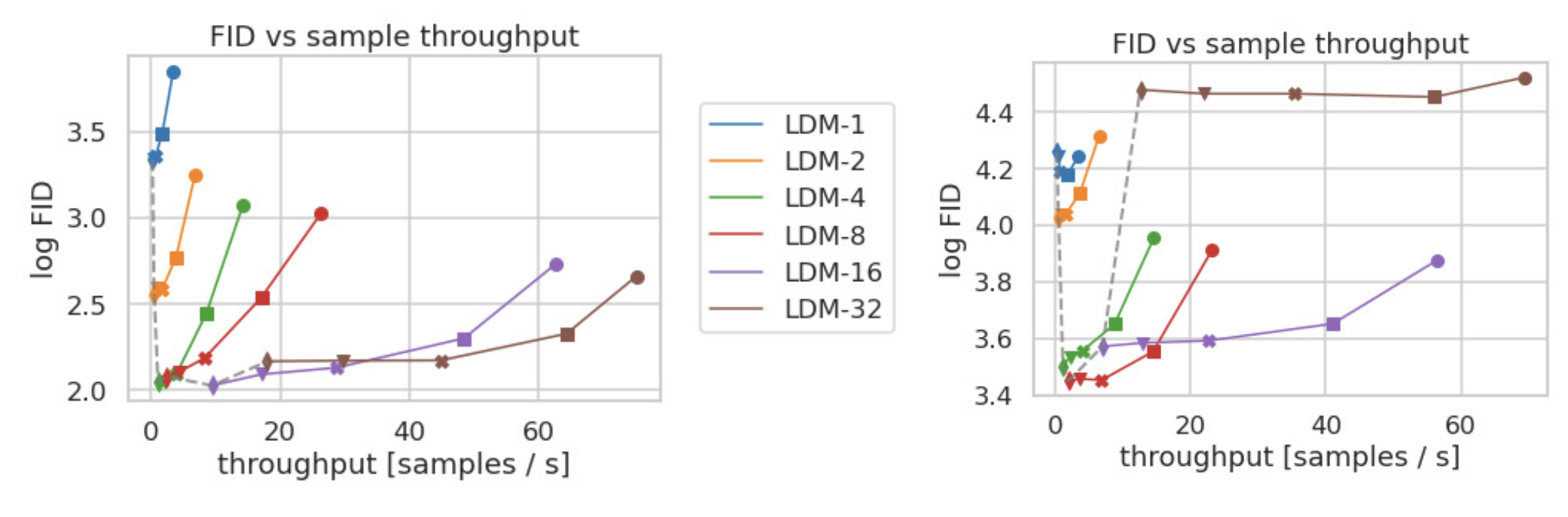
The LDM also demonstrated better sampling efficiency. Moreover, it generates samples faster and at a higher quality.
References
(Citations removed)