Introduction
SAM is a big collection of models published by Meta AI and it aims to segment components from contents. It originally started with image segmentation but gradually expanded to video, 3D geometry (opens in a new tab) and audio (opens in a new tab).
In this post, we will focus on the image and video segmentation models. Segmentation is a quite classic task in computer vision and it has been extensively studied for decades. But SAM series models revolutionized the field in following ways:
- From expert model to foundation model: Traditional segmentation models are usually trained for a specific task or dataset. SAM introduced a "Promptable Segmentation" task and does not require any fine-tuning for zero-shot segmentation.
- Unprecedented dataset scale and strong generalization ability: Previous models are usually trained on about ~100k images and ~1M masks. SAM v1 is trained on 11M images and 1.1B masks, which exceeds the scale of previous datasets by more than 100x.
The SAM series models are evolving over time and here is a summary of the key facts:
| Version | Goal / Task | Key Contributions |
|---|---|---|
| SAM (Segment Anything) | Promptable Segmentation Task To return a valid segmentation mask given any prompt (point, box, mask, text) on a static image. Aimed at zero-shot generalization to new distributions. | • Model: Proposed the SAM architecture (Heavy Image Encoder + Light Prompt Encoder/Mask Decoder) for real-time interaction. • Data: Created SA-1B dataset (11M images, 1.1B masks) using a 3-stage data engine (Manual Semi-Auto Fully Auto). |
| SAM 2 | Promptable Visual Segmentation (PVS) To unify image and video segmentation. Extends the "segment anything" capability to video by maintaining temporal consistency and handling object occlusions/re-appearance. | • Model: Introduced a streaming architecture with Memory Attention and a Memory Bank to condition outputs on past frames. • Data: Created SA-V dataset (51K videos, 642K masklets) using a model-in-the-loop data engine. • Performance: Faster (6x speedup over SAM) and more accurate in both image and video domains. |
| SAM 3 | Promptable Concept Segmentation (PCS) To segment all instances matching a specific concept (text phrase or visual exemplar) in images and videos. Moving from "segment one specific target" to "segment all matching targets". | • Model: Introduced a decoupled architecture with a Detector (for recognition) and Tracker (from SAM 2), plus a Presence Head to separate recognition from localization. • Data: Created SA-Co dataset (1.7B image-concept pairs) with 4M+ unique concepts specific to semantic understanding. |
SAM v1: Promptable Segmentation and Scalable Data Generation
Define the task
To serve as a fundation model in image segmentation, it should have strong capability of generalization. For this purpose, the authors defined a "Promptable Segmentation" task: given an image and a prompt, the model should return the segmentation result.

To achive this goal, there two main issues to resolve:
- What is the architecture of the model? It should be able to process both the image and the prompts and efficiently interact with the prompts.
- How to generate sufficient high quality training data and train the model? High quality training data is critical and very scarce before this work. This work designed a model-in-the-loop data engine and iteratively generate data and train the model.
- How to deal with the ambiguity of the prompts? A point on a human face can mean both the face or the entire body. To deal with this ambiguity, the authors proposed to predict multiple candidate masks for each prompt.
SAM v1 model architecture
Remarks:
- Image Encoder module:
- At the training time, the parameters in the image encoder are learnable. Based on empirical observation of MAE-pretrained ViT-H/16, finetuning(make the parameter learnable) can yield much better performance than linear probing(freeze the parameters and use encoder as fixed feature extractor).
- Prompt Encoder module:
- For text, the authors use a frozen CLIP Text Encoder for zero-shot text-to-mask transfer.
- Training: Since SA-1B has no text, they use the CLIP Image Encoder (frozen) on random crops around masks to generate "pseudo-text" prompt embeddings.
- Inference: They use the CLIP Text Encoder (frozen) on the input text. Because CLIP aligns image and text spaces, this works zero-shot without explicit text supervision.
- For text, the authors use a frozen CLIP Text Encoder for zero-shot text-to-mask transfer.
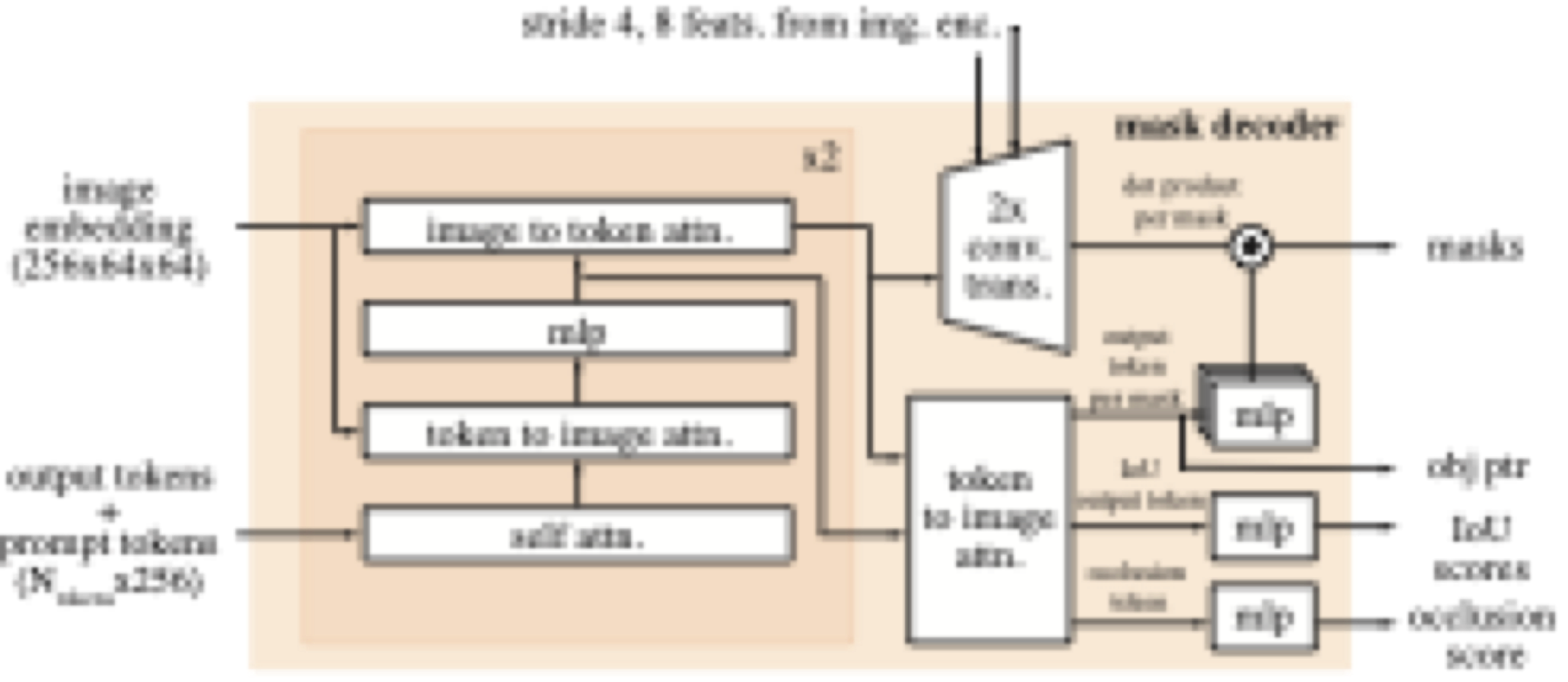
- Mask Decoder module:
- There are 4 learned tokens (1 IoU + 3 Mask) that act as "queries". Initially identical for all inputs, they gather information from the image and prompts via the Transformer's attention mechanism. They can be percieved as [CLS] tokens or registers in ViT. I did not find any part in the paper that indicates that each of this output token is represent "query" to a specific output mask. For example, learned output token 1 represent query for "whole object" mask. Therefore, I think it does not matter a lot if there is 3, 4, 5, or even 6 output tokens.
- The transformer module inside the mask decoder combines the self-attention and cross-attention. My understanding about the architure is this (opens in a new tab).
Data Engine and training recipe
The final dataset the paper generated has more than 1.1B masks and it is impossible to manually label all of them (napkin math: 1.1B* 50s per mask(estimated in the paper) = 1500 years). In this paper, the authors proposed a model-in-the-loop(MITL) style training strategy to iteratively train the model and generate dataset. It started the training with some public segmentation datasets (the paper did not specify, but I assume it is COCO, LVIS, etc) and obtained an very initial version of SAM. Then iteratively generate masks, annotate them with human annotators, and retrain the model. Detailed process is shown in the figure below.
Stage 1: Assisted-Manual
Focus: Human-in-the-loop
Input: Initial SAM trained on public datasets
- Professional annotators use browser-based tool
- Click fg/bg points → SAM predicts mask
- Refine with brush/eraser
Feedback: Retrain SAM 6 times (ViT-B → ViT-H)
Output: 4.3M masks / 120K images
Stage 2: Semi-Automatic
Focus: Diversity
Input: SAM + Box Detector
- Auto-detect confident objects
Annotators add additional objects
Feedback: Retrain SAM 5 times
Output: 5.9M new masks / 180K images (10.2M total)
Stage 3: Fully Automatic
Focus: Scale (Zero human effort)
Input: SAM with ambiguity-aware output
- 32×32 point grid prompt
- Predict 3 masks/point
- Filter by IoU/Stability/NMS
Feedback: None
Output: 1.1B masks / 11M images
SAM v2: Unified Video and Image Segmentation
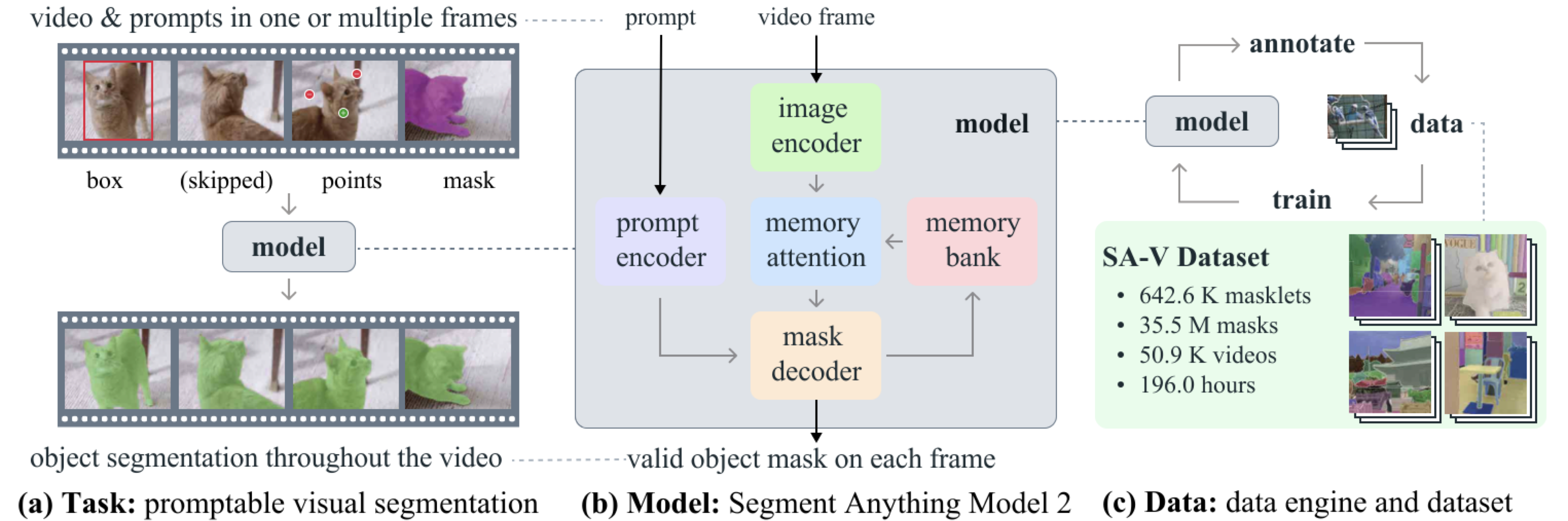
Define the task
Moving from static images to dynamic videos, the authors introduced the Promptable Visual Segmentation (PVS) task. The goal is to extend the "Promptable Segmentation" capability to the temporal dimension:
- Input: Prompts (clicks, boxes, masks) on any frame of a video.
- Output: A valid spatio-temporal masklet (a 3D mask across time) for the target object.
- Goal: Consistent across different frames and flexible for interactive. It should be able to handle a variety of challenges in video segmentation, such as object appearance changes, occlusions, and background clutter.
PVS unifies image and video segmentation because an image is simply a 1-frame video.
The PVS task requires segmenting an object across video frames given prompts on any frame.
SAM v2 model architecture
The core challenge in video is Memory: "What did the object look like in previous frames?" and "Where was it?". SAM v2 introduces a streaming memory mechanism to solve this.
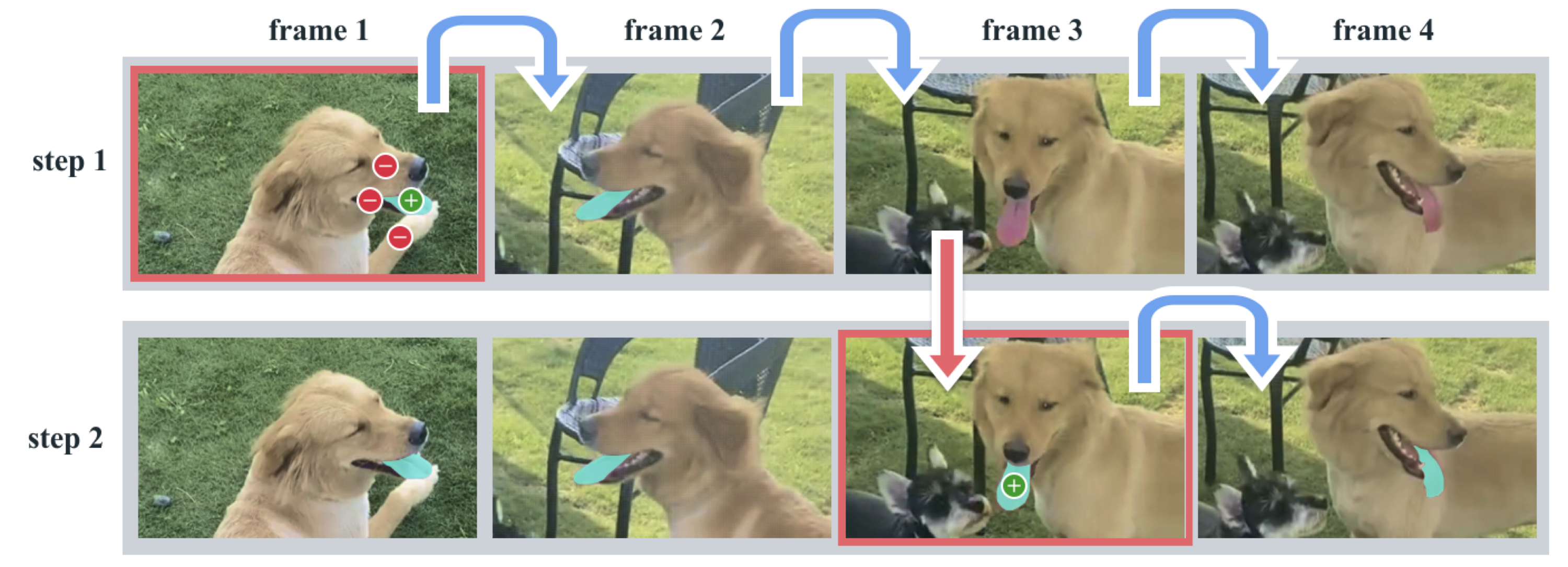
Remarks:
- Hiera Backbone: SAM v2 uses Hiera, a hierarchical Vision Transformer, instead of the plain ViT in SAM v1. This allows for multiscale features and is significantly faster, enabling real-time video processing.
- Streaming Memory:
- Spatial Memory: The model stores "fused" feature maps of the image and the predicted mask from past frames. This captures "where" the object was and "what" it looked like.
- Object Pointers: Lightweight vectors (from the mask decoder output tokens) that capture high-level semantic information (the "identity" of the object) to prevent drifting to similar looking distractors.
- Memory Bank: A FIFO queue stores the last frames of spatial memory and up to "prompted" frames (frames where users explicitly interacted).
- Occlusion Handling: A new head predicts whether the object is visible (occluded) in the current frame. If occluded, the model can "skip" predicting a mask but still maintain memory.
Data Engine: SA-V Dataset
To train this video foundation model, the authors built the SA-V dataset (~51K videos, ~643K masklets). They used a similar Model-in-the-Loop scheme as SAM v1, but adapted for video.

Comparison of manual annotation (left) vs. Model-assisted annotation (right).
Phase 1: SAM per frame
- Annotators use SAM v1 to segment object in every single frame.
- No temporal tracking assistance.
- Very slow (37.8s / frame) but high quality.
Phase 2: SAM + SAM 2 Mask
- Annotators segment one frame with SAM v1.
- SAM 2 Mask (accepts only mask prompts) propagates prediction to other frames.
- Refine errors by re-segmenting frames from scratch.
- 5.1x faster.
Phase 3: SAM 2
- Annotators use the full SAM 2.
- Click/Box on any frame to valid/correct the track.
- Memory mechanism handles consistency.
- 8.4x faster than Phase 1.
SAM v3: Segment Anything with Concepts
Define the task
While SAM v1/v2 excel at "Segment this object" (where this is defined by a click), they struggle with "Segment all cats". SAM v3 introduces Promptable Concept Segmentation (PCS).
- Goal: Segment all instances matching a specific concept.
- Input:
- Text: "Yellow school bus", "Person wearing red shirt".
- Visual Exemplar: A box around one instance of the object.
- Output: Masks and unique IDs for all matching objects in the image or video.

Promptable Concept Segmentation: Segmenting all instances of a concept defined by text or visual exemplar.
This bridges the gap between Generic Segmentation (SAM) and Open-Vocabulary Detection (OWL-ViT, GroundingDINO).
SAM v3 model architecture
The core innovation is "Shared Eyes, Split Brain". A single image backbone supports two distinct tasks: Detection (Category-aware, Identity-agnostic) and Tracking (Identity-aware, Category-agnostic).
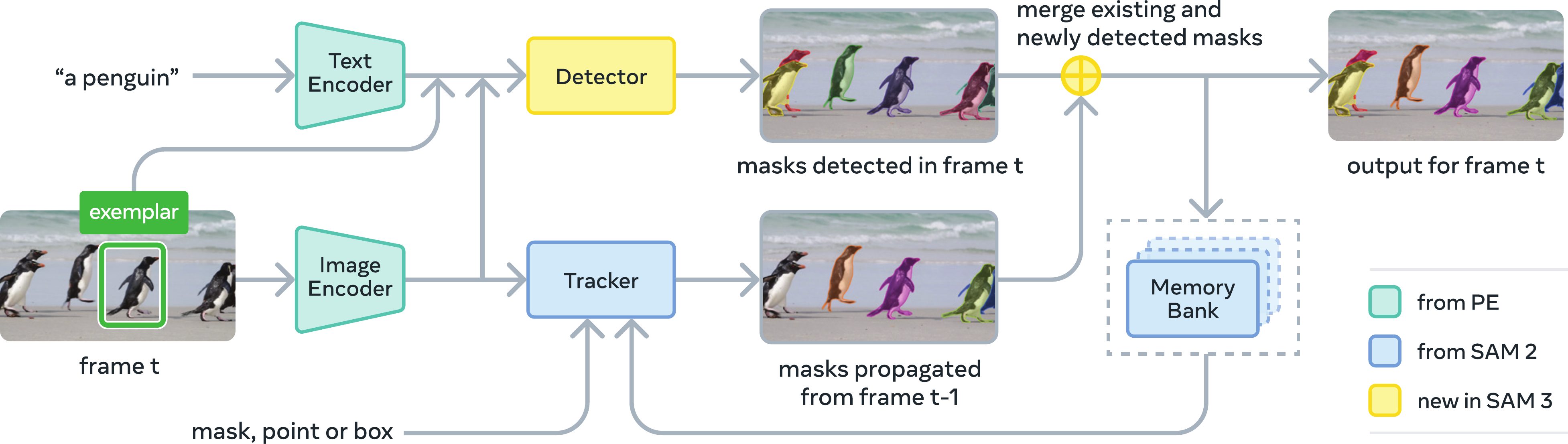
Remarks:
- Shared Perception Encoder: Uses a high-performance vision-language backbone (Bolya 2025) that is effective for both tasks.
- The "Presence Head":
- A classic problem in open-vocabulary detection is Hallucination. If you ask a model to find "dragons" in an empty room, standard detectors force their queries to find the "most dragon-like" patch, often yielding false positives.
- SAM v3 adds a Global Presence Token that first predicts: "Is the concept 'dragon' present in this image at all?".
- The final score for an object is . If the Presence Head says "No", all object scores drop to zero.
- Unified Logic: The Detector finds objects, and the Tracker (inherited from SAM 2) propagates them through time.
Data Engine: SA-Co Dataset
To solve the scale and ambiguity of concepts, Meta built the SA-Co (Segment Anything with Concepts) dataset (~4M concepts). The data engine focuses heavily on AI Verification to scale up.
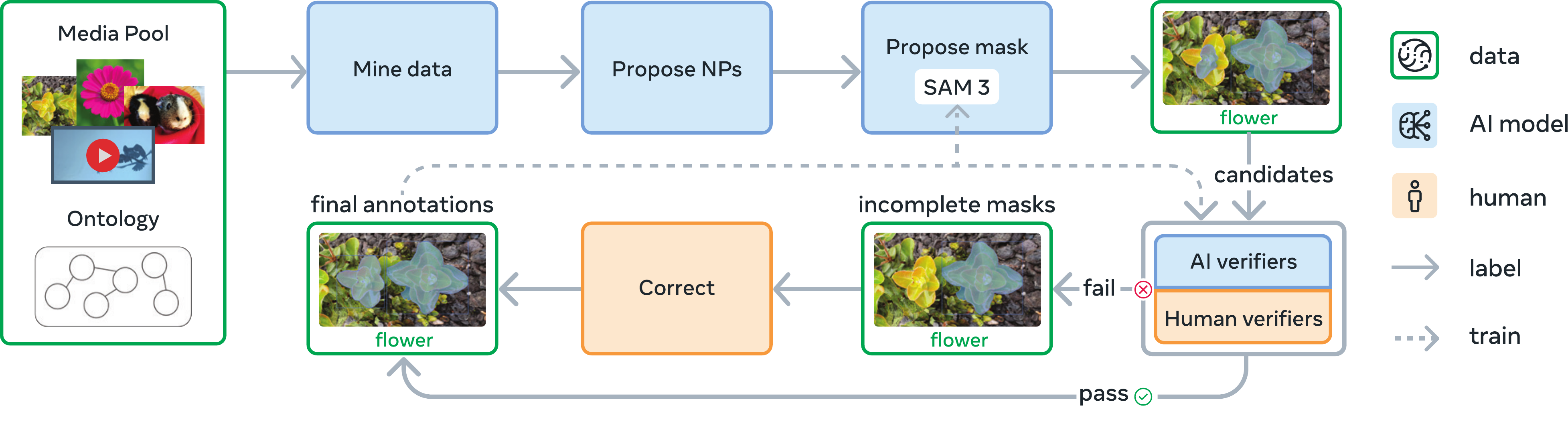
The SA-Co Data Engine pipeline, featuring human and AI verification stages.
Phase 1: Human Verification
- Input: Noisy image-text pairs.
- Action: Human annotators verify mask quality and exhaustivity (did we catch all instances?).
- Outcome: ~4.3M high-quality pairs. Used to train initial models.
Phase 2: AI Verification
- Innovation: Replaced humans with Llama 3.2.
- Fine-tuned Llama on Phase 1 data to act as a "Verifier".
- It rates masks as "Correct/Incorrect" and checks exhaustivity.
- Result: Doubles the throughput of the data engine.
Phase 3: Scaling & Ontology
- Expansion: Mining concepts from image alt-text and a massive Wikidata knowledge graph.
- Introduction of Hard Negatives (e.g., if prompting for "Lion", ensure the model doesn't click "Tiger").
Phase 4: Video
- Extends the engine to video by sampling frames, annotating them, and propagating with SAM v2.
- Prioritizes crowded scenes and motion to capture hard tracking cases.
References
- SAM: arXiv:2304.02643 (opens in a new tab) - Segment Anything
- SAM 2: arXiv:2408.00714 (opens in a new tab) - Segment Anything Model 2
- SAM 3: arXiv:2511.16719 (opens in a new tab) - Segment Anything Model 3